Adaptive RAG
A full-stack retrieval-augmented generation platform that ingests PDFs, generates sentence-level embeddings, and returns grounded answers with page-level source citations. Five vector pruning strategies plus a live pipeline inspector.
Pipeline inspector and chat interface
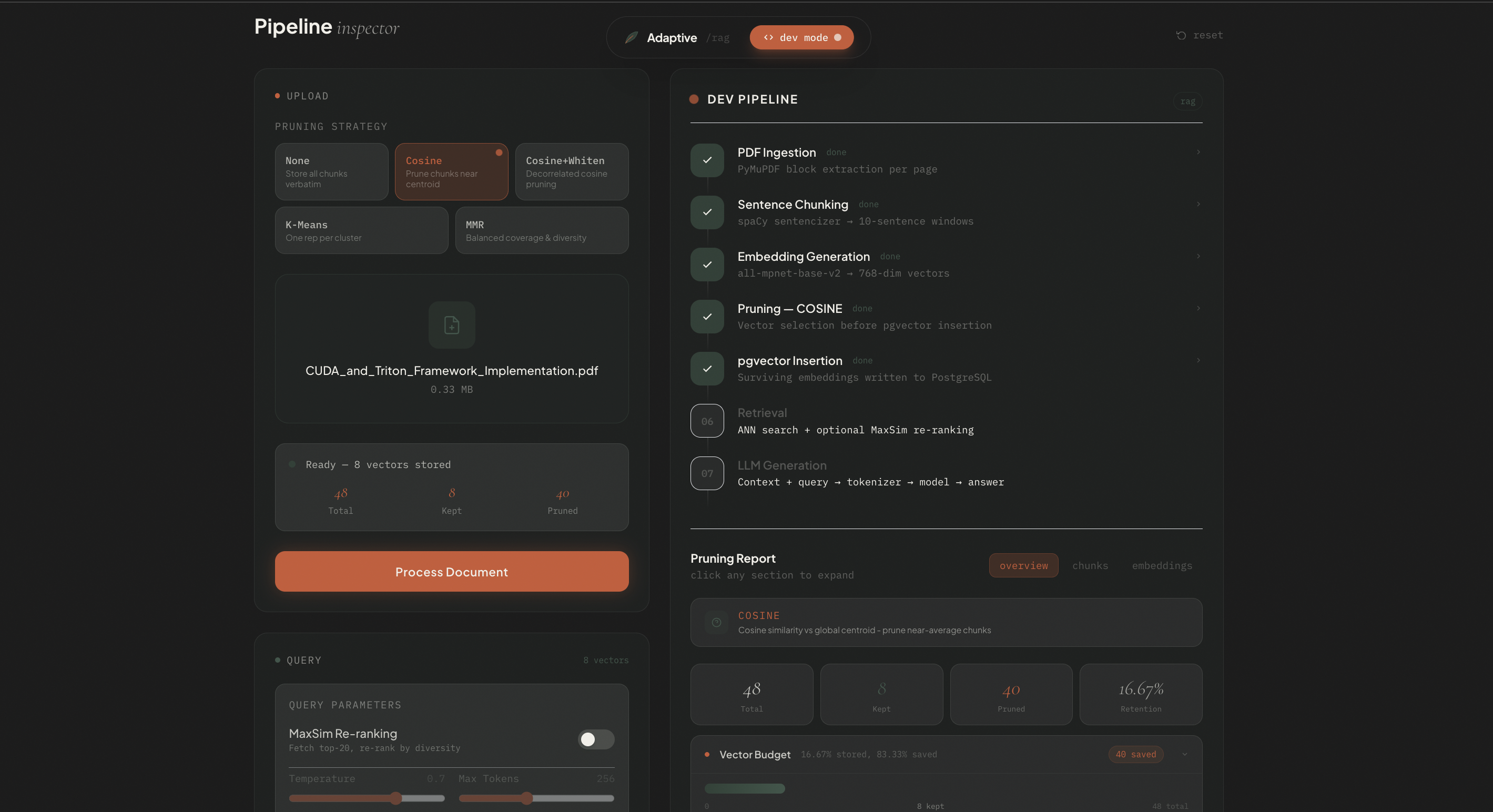
Embedding visualizer and pruning report
PDF Ingestion
Drag and drop upload. Documents are chunked at the sentence level with overlap windows for maximal recall.
Embedding Engine
768D sentence-transformer embeddings stored in pgvector. Supports cosine, whitened cosine, k-means, and MMR retrieval.
Five Pruning Strategies
Cosine, Cosine Whitened, K-Means Clustering, MMR, Threshold. Switchable at query time via the UI.
Dev Mode
Live pipeline inspector exposes per-chunk pruning reports and an interactive 768D embedding visualizer.
Grounded Answers
Every response is anchored to page-level citations. No hallucination without a traceable source.
Stack
FastAPI, pgvector (PostgreSQL), Next.js, TypeScript, sentence-transformers, OpenAI
Problem
Standard RAG pipelines retrieve too many irrelevant chunks, inflating context and degrading answer quality. Adaptive RAG lets you tune the pruning strategy per use-case.
Architecture
Decoupled FastAPI backend handles all ML inference. Next.js frontend streams answers via SSE. pgvector handles ANN search with IVFFLAT indexing.
My contribution
Built the full frontend, including the pipeline inspector, embedding visualizer, and chat interface. On the backend, worked on the cosine similarity, cosine similarity whitened, and k-means clustering pruning strategies.